Introducing VideoNotes: Your Ultimate AI-Powered Youtube-to-Notes Companion!"

I am a developer from India with a good eye for frontend logic and design. I am also well acquainted with the backend and business logic so that's add to my ability to create a good frontend while making it easily integratable with backend.
Hey there, everyone! How's your week treating you? As for me, I must admit, it's been quite tiring. I recently embarked on a new adventure by landing a full-time job—cue the applause and congratulatory comments, if you feel like it! Let me tell you, it's been quite the whirlwind. The days have been jam-packed and filled with a flurry of activities.
By the way, during my college days, I found myself engrossed in numerous informational videos and lectures. Let me tell you, trying to take notes while absorbing all that knowledge was no walk in the park. The struggle was real! I often wished for a magical AI companion who could effortlessly jot down the key points for me. Can you imagine how incredible that would be? It would have saved me from the mindless consumption of content without any real progress. And when the opportunity came for this hackathon by 1Password and Hashnode I couldn't refuse to participate
The Genesis of Incredible Idea 💡
After the launch of ChatAI, I wanted to get my hands dirty and try out a bunch of AI mini SAAS tools for my productivity. And a way to jot down the notes from youtube was first on my priority list. And when OpenAI launched the GPT-3 API I jumped at the opportunity to build something cool.
The concept behind Video-notes is to provide a convenient SaaS tool that allows users to simply paste a YouTube link and automatically generate comprehensive notes while watching the video. However, why limit ourselves to just note generation? Let's think bigger! Why not expand the capabilities of the tool to include generating blog posts, summaries, transcripts, and even language translation? With such a versatile tool, the possibilities for enhancing productivity and content creation become truly endless.
That's what Video-Notes is, It's not a boring transcriber for your youtube video but auto-formatting the Transcription to your desired Output using the power of AI.
Doesn't it seem amazing?
Video Preview
The Journey 🛣️
The journey to create this was pretty tiring it was hard to come up with a good architectural design that can be cost-effective as well as fast. Even though below is what I can come up with.
The Architecture ⚒️
Passage by 1Password
Passage feels very intuitive to me as it provides a native way to log in to any application and you don't need to remember the password at all. How cool is it?
Also, the Implementation was pretty simple and straightforward, You can say probably one of the best ways to authenticate your users.-
To get the Audio file from the URL of the youtube link I used the YTDL library. In the beginning, I was fetching the audio from Youtube using the YTDL API, and once the audio was received, I streamed and saved it to my in-memory state ( basically state if you use React).
The Problem with this approach was I was streaming a big file back to my react app and not only that I needed to send this file back to the Whisper to get the Transcription.
-
In the beginning, I transcribed the Video from youtube using, OpenAI's product whisper. This worked perfectly for smaller videos but not for larger files as it has a file limit of 25MB (Roughly around ~25min high-quality videos). But any good lecture video or educational video generally exceeds more than 200 MB or more. So I initially thought of chunking the audio into 25 MB chunks and getting the transcription one by one.
This solution was possible but the problem was that it was not very fast in real-world scenarios. No user wants to keep waiting for half an hour ( Yes it took this long) and also the cost to use the whisper API was quite a lot which was not sustainable in the long run.
This was the main reason why I moved away from the whisper API. This did the job accurately but also had a very high cost associated with it. -
I don't really think you haven't heard of chatGPT, if you haven't let me tell you it's an amazing generative AI by OpenAI. Now this could solve a ton of my problem like, like converting the transcripts to the Blog, Summaries, and Notes, or even translating it into another language. Basically, it's the Brain of the whole application. and very essential part of the whole architecture.
-
I used the Firebase product Firestore to save the data like user details and notes details and other stuff. Which I might need to show users in the future.
The Improvision
After looking at the above implementation I knew it was not going to sustain itself, even users would think it was an overpriced application if I ever decide to monetize it. Now I needed to search for a solution that can reduce the cost that was associated with Whisper API also the circus I had to go through only to fetch the transcription of the Youtube video.
Youtube does it for free.
I told this problem to my friend he was like dude youtube does that for free. Don't you know? And I was like yes I agree but is it that accurate? I don't think so, and then he mentioned "You don't need accuracy you need Transcription" As we were already using the ChatGPT we can post-process the data using it, so any issue with the transcription will be solved automatically.
Using Youtube's auto-cc as Transcription.
I used the YTDL library to do that. Here is a snippet of what I did, I used Nestjs API to do that as YTDL uses fs to run so it was throwing an error in the client so to workaround this used the Next API.
import ytdl from "ytdl-core";
import { NextApiRequest, NextApiResponse } from "next";
import { parseString } from "xml2js";
const lang = "en";
const format = "xml";
// eslint-disable-next-line import/no-anonymous-default-export
export default async (req: NextApiRequest, res: NextApiResponse) => {
const { url } = req.query;
ytdl.getInfo(url as string).then((info: any) => {
const tracks =
info.player_response.captions.playerCaptionsTracklistRenderer
.captionTracks;
if (tracks && tracks.length) {
const track = tracks.find(
(t: { languageCode: string }) => t.languageCode === lang
);
if (track) {
fetch(`${track.baseUrl}&fmt=${format !== "xml" ? format : ""}`)
.then((response) => response.text())
.then((xmlData) => {
// Parse XML to JSON
parseString(xmlData, (err, result) => {
if (err) {
console.error("Error parsing XML:", err);
res.status(500).send("Error parsing XML");
return;
}
// Convert JSON to plain text
const plainText = result.transcript.text;
const response = {
transcript: plainText,
simpleText: convertToSimpletText(plainText),
};
res.send(response);
});
})
.catch((error) => {
res.status(500).send("Error fetching captions");
});
} else {
res.status(400).send("Could not find captions for " + lang);
}
} else {
res.status(400).send("No captions found for this video");
}
});
};
function convertToSimpletText(transcriptData: any) {
let text = "";
for (const { _: line } of transcriptData) {
// Remove unnecessary data (e.g., speaker names)
const cleanedLine = line.replace(/\[[^\]]+\]/g, "").trim();
text += cleanedLine + " ";
}
return text.trim();
}
Let me quickly explain to you what is happening in the above code. So first we are using YTDL to fetch the video info from the URL our user has given, once we have that we are making another nested api call to the other API which basically fetches the CC in xml format.
fetch(`${track.baseUrl}&fmt=${format !== "xml" ? format : ""}`)
The Response is received it looked like the below and we need some pre-processing to send this data to the GPT-3.
/**
* Notes : Result
* Transcript: [
{
_: '[Herb, YouTuber]\nThis video demonstrates closed captions.',
'$': { start: '6.5', dur: '1.7' }
},
{
_: 'To turn on captions, click on the icon over here.',
'$': { start: '8.3', dur: '2.7' }
},
{
_: '[Greg, Deaf Singer]\n' +
'Back when the Internet was first established, deaf people had a\n' +
'great time with it.',
'$': { start: '12.5', dur: '3.9' }
},
{
_: 'Everything was readable.\nThen ...',
'$': { start: '16.5', dur: '2' }
},
{
_: '[Ken, Deaf Listener]\n' +
'Movies started showing up.\n' +
'We couldn't understand them...',
'$': { start: '19', dur: '3.2' }
},
{ _: 'there were no captions!', '$': { start: '22.5', dur: '1.5' } },
{
_: 'Fortunately, Google Video added support for captions.',
'$': { start: '24.5', dur: '2.5' }
},
{ _: 'Thank you, Ken!', '$': { start: '27.5', dur: '1' } },
{
_: 'Now, we've added that to YouTube.',
'$': { start: '28.5', dur: '3' }
},
{
_: 'But the first thing he did with\nthat was RickRoll me!',
'$': { start: '32', dur: '3' }
},
{
_: '♪ Never gonna give you up, ♪\n♪ never gonna let you down...',
'$': { start: '35.5', dur: '3.5' }
},
{
_: '[Franck, Icone de Mode]\nCaptions and subtitles are also helpful',
'$': { start: '41.3', dur: '2.7' }
},
{
_: 'for people who speak other languages, like myself.',
'$': { start: '44.2', dur: '2' }
},
{
_: 'With subtitles, I can enjoy US Comedy, or news stories from Russia,',
'$': { start: '46.8', dur: '3.2' }
},
{ _: 'in my own language. ', '$': { start: '50.1', dur: '1.4' } },
{
_: 'As a video uploader, this means you can reach\n' +
'to people all over the world, ',
'$': { start: '52', dur: '4' }
},
{
_: 'irrespective of language.',
'$': { start: '56.8', dur: '1.7' }
},
{
_: '[Hiroto, Bedhead]\n' +
'You can upload multiple tracks like English and French, ',
'$': { start: '59.5', dur: '2.5' }
},
{
_: 'and viewers can choose the track they like.',
'$': { start: '62.5', dur: '3.5' }
},
{
_: '[Toliver, Japanese Learner]\n' +
'For example, if you enjoy using YouTube in French,',
'$': { start: '67.5', dur: '4' }
},
{
_: 'French captions will automatically appear.',
'$': { start: '72', dur: '5' }
},
{ _: 'With just a single video,', '$': { start: '77.5', dur: '3' } },
{
_: 'you can now reach people all around the globe!',
'$': { start: '81', dur: '5' }
},
{
_: 'The captioning capability at YouTube was just launched this summer,',
'$': { start: '88', dur: '3' }
},
{
_: 'and we're planning to add more features to this.',
'$': { start: '91.3', dur: '2.7' }
},
{
_: 'If you have any feedback, please let us know!',
'$': { start: '94.2', dur: '2.3' }
}
]
*
*/
It has duration as relevant data which I m thinking to use but for now we just simple data string which we can send to the GPT-3 API.
Pre-Processing
function convertToSimpletText(transcriptData: any) {
let text = "";
for (const { _: line } of transcriptData) {
// Remove unnecessary data (e.g., speaker names)
const cleanedLine = line.replace(/\[[^\]]+\]/g, "").trim();
text += cleanedLine + " ";
}
return text.trim();
}
Once this data is saved to the state, I make the call to GPT-3 API using the data we got in Step 1.
We use a simple GPT-3 completion API Read about it HERE.
export const getGptResponse = async (
text: string,
contentType: string
): Promise<string | undefined> => {
if (!text) return;
return new Promise((resolve, reject) => {
fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${getApiKey()}`,
},
body: JSON.stringify({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: contentType,
},
{
role: "assistant",
content:
"Supported Markdown: #, ##, ###, ####, #####, ######, , >, *, 1. , ```code```,",
},
{
role: "user",
content: text,
},
],
}),
})
.then((response) => {
if (!response.ok) {
throw new Error("Network response was not ok");
}
return response.json();
})
.then((json) => {
console.log(json.choices[0].message.content);
resolve(json.choices[0].message.content);
})
.catch((error) => {
console.log(error);
reject(new Error("GPT-3 failed"));
});
});
};
In this, I fetch the key From the local storage and then make the API call with the transcription data in the first Step.
Once that is done I need to do an extra step to convert the markdown to the Blocks data. which my editor understands. Why Markdown? Surprisingly CHAT GPT is very good at handling markdown than the data is needed.
Once the Editor is populated with the data user wants just SImply saves it and can easily access it from any device anytime.
So where does the Passage Come In?
Well as we are saving the notes and making API calls to OpenAI which is expensive, we do want some kind of user management. There are a ton of ways to handle it, including the Firebase auths, but what Passage gave seems very intuitive and native to having an application experience. It simply uses the native way of the device to authenticate users and login them.
Just not that also the implementation was pretty simple and I was blown away by how easy the implementation was, Barely a couple of lines of code. you can read about it in their official doc.
Application Flow
Visit Us.
Go to https://video-notes-pi.vercel.app/ and Click on Get Started.
Login Using Passage
If you are already login you can continue normally using your native way or you can register.
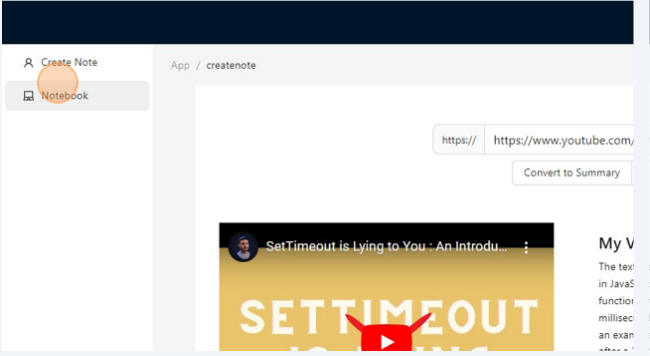
Enter the URL of your youtube Video.
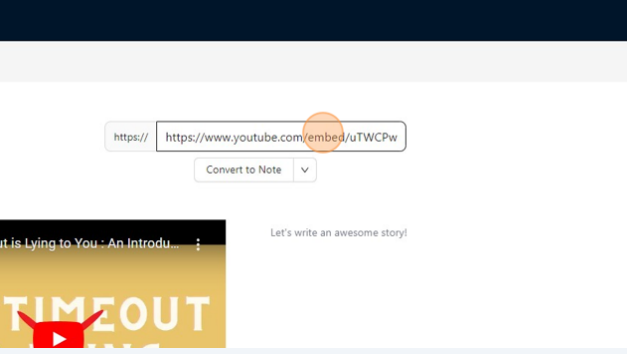
Select the format You want.
Select the format you like to have your output in, In this example, I used Summary as my desired format, you can choose others too, We currently support Notes, Blogs, and Summary though planning to have others and a custom option too. Where you can write your own prompts.
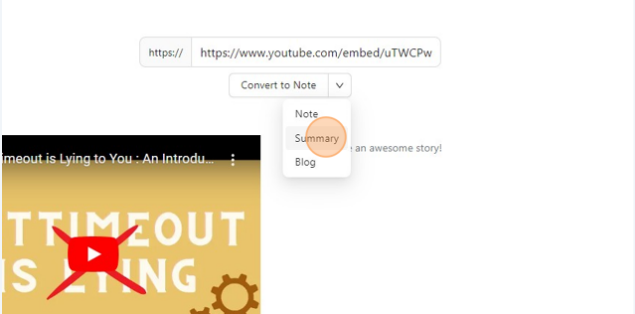
Click and Wait for it...
Once you clicked on Convert, you kind of need to wait for this process to finish, once that is done you will have a screen like below.
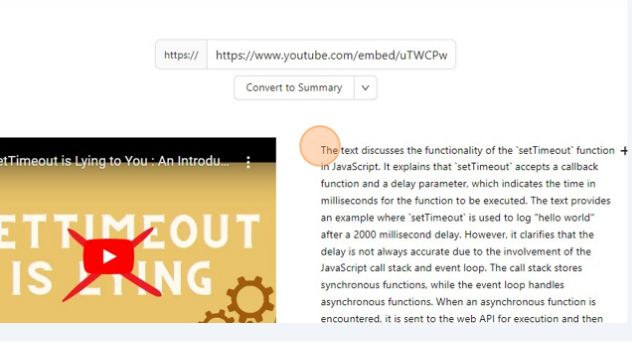
Save the Note to the Database.
You can click Save to save to Firebase or you can edit it, it's up to you.
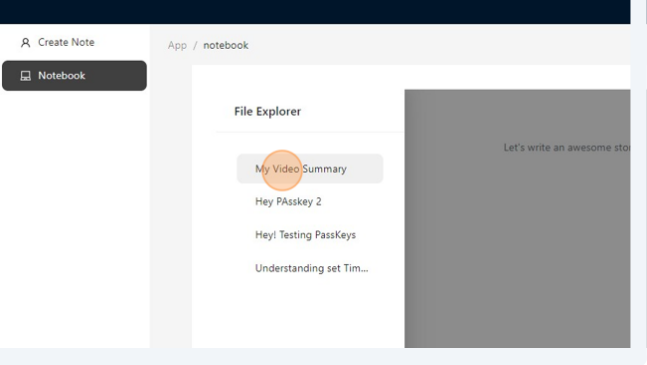
Revisit it.
You can revisit your saved notes by clicking on the Notebook and then selecting the note you wanna revisit.
Results

What's Next
A Better Player: I Intent to add a better player for playing and navigating the youtube video in sync with the notes or blogs.
A Better Editor: I intended to add better features to the editor, like code preview, automatic screenshots, etc.
Timestamp-based Notes: I also planning to add a feature in which we can add timestamps to our notes or transcript so that it's easily navigated.
Better Prompts and Custom Prompts: Better support for custom prompts and increasing the quality of the existing prompts.
Translation: A way to get the videos that are not native and transcribe them.
Technology Used 🧑💻
Frontend
Editor.js
Free block-style editor with a universal JSON output.
Backend and API
Resources and links
TLDR
Video-Notes is a SaaS tool that generates notes from informational videos.
It offers features like blog post generation, summaries, transcripts, and language translation.
Technical implementation includes:
Authentication using Passage.
Fetching audio from YouTube using YTDL.
Transcription using YouTube's auto-cc (switched from Whisper API).
ChatGPT as the core language model.
Data storage using Firebase.
Code snippets for fetching auto-cc from YouTube and using the GPT-3 API were shared.
Improvements were made to reduce costs and enhance transcription accuracy.
Live version: Live Video-Notes
GitHub repository: Video-Notes on GitHub